
分類の指標
機械学習の分類(クラスタリング)において、「十分な精度で学習できているか」をどのように判定するできるのでしょうか?
それは、評価指標として、正解率、適合率、再現率、F値を使用されます。
今回はその指標について説明していきます。
分類結果を確認する
機械学習の分類(クラスタリング)の結果をまとめました。
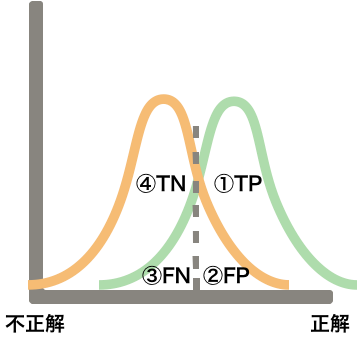
以下の4パターン考えられます。
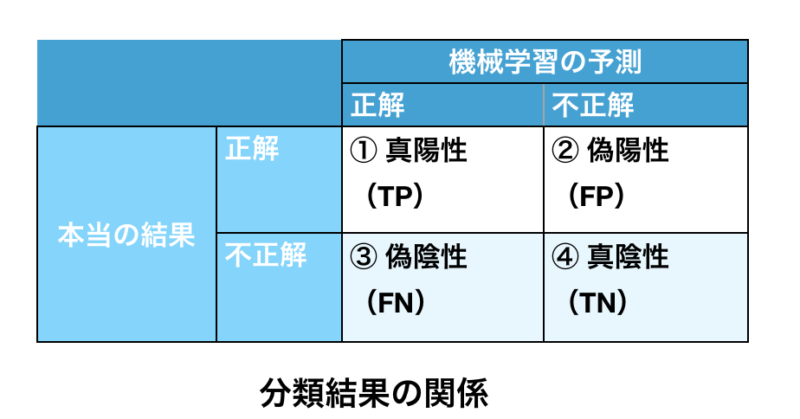
① TP(True Positive):
機械学習の予測(本当に正解)が合っている。
② FP(False Positive):
機械学習の予測(機械学習モデルが不正解と予測)も合っていない。
第一種過誤、α過誤とも言います。
③ FN(False Negative):
機械学習の予測(機械学習モデルが正解と予測)も合っていない。
第二種過誤, β過誤とも言います。
④ TP(True Negative):
機械学習の予測(本当に不正解)が合っている。
※Positive=これが正解だと予測した 。Negative=これは不正解だと予測した。
ではこの分類の結果をどのように評価できるかを考えてみましょう!
評価指標
① 正解率(Accuracy)
正解率
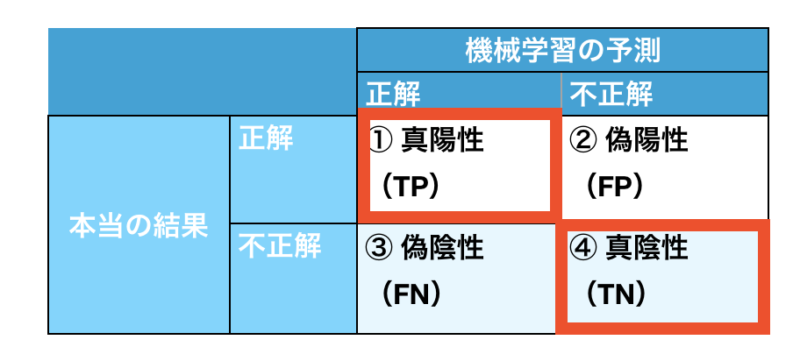
正解率 = TP+TN / 全体
全データのうち、正解したデータ数の割合です!
一番わかりやすい指標です。
② 適合率(Precision)
精度とも言います。
適合率
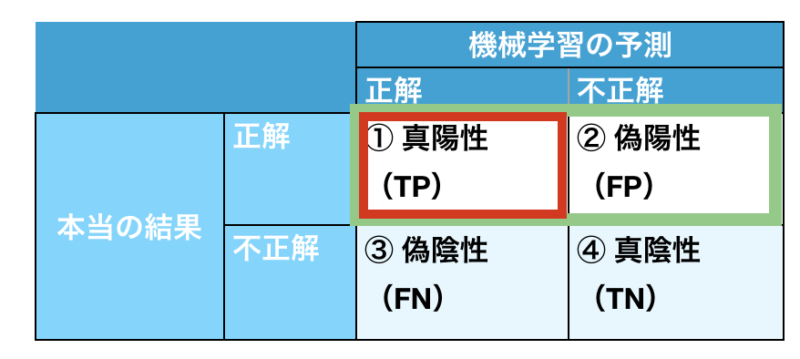
適合率 = TP / TP+FP
本当に正解の数のうち、それが機械学習の予測としても正解している割合です!
③ 再現率(Recall)
感度、検出力とも言われます!
再現率
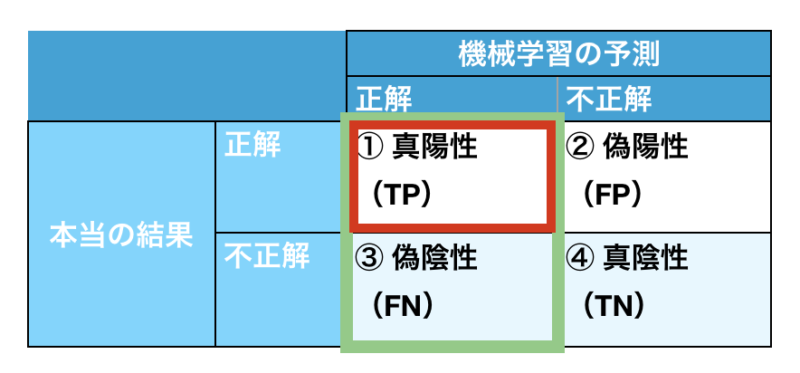
再現率 = TP / TP+FN
機械学習の予測で正解のうち、本当の結果も正解している割合です!
色々と指標ありますね!どれをみたらいいのか迷いますね・・
総合的な指標として見るとすると、F値になります!
F値 (f1-score)とは?
2つの評価指標(適合率と再現率)を踏まえた統計的な値となります。
F値 = 2×(Precision × Recall) / (Precision + Recall)
これは適合率(Precision)と再現率(Recall)の調和平均となります!
※調和平均とは、逆数の平均の逆数(以下のようなイメージ)
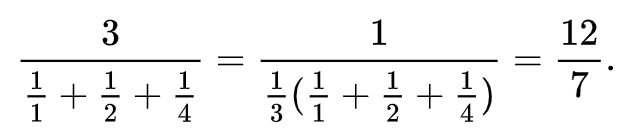
F値の範囲としては0から1の間に収まり、F値が高いほど良いと言われます。
(高いに明確な値はありませんが・・)
またF値が調和平均で計算される理由としては再現率と適合率に対してトレードオフ(どちらかの結果がよければ、片方が悪くなる)関係があるため、普通の平均ではうまく計算できないためです。
トレードオフの関係
まとめ
分類のモデルをどのように評価するかの指標をみてきました。
割とよく使用されるので、ぜひ抑えておいて欲しいです(^ ^)
機械学習で色々とできるようになりたいと思っている方は無料カウンセリングもありますので、TechAcademyのはじめてのAIコースを受けてもいいかもしれません(^ ^)
ぜひ頑張って勉強しましょう!
