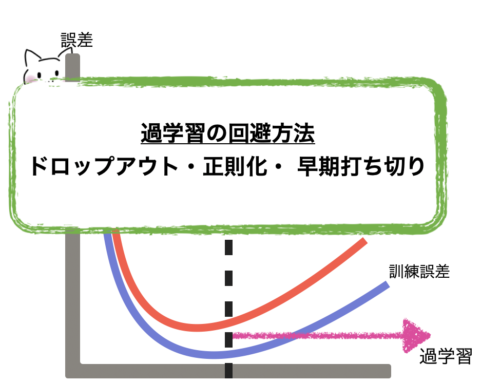
過学習とは
機械学習で学習させすぎて、訓練データでは正解率が高いが、訓練データ以外だと正解率が下がってしまう事です。
つまり、訓練データだけに最適化されてしまい、汎用性がなくなる事です。
特にニューラルネットは複雑なモデルのため、過学習に起こりやすいそうです。
今回は過学習を防ぐ方法を紹介します(^ ^)
ドロップアウト(Dropout)
ニューラルネットワークを学習する際にある更新で層の中のノードのうちのいくつかをランダムに無効にして学習を行う事です。
ドロップアウトのイメージ
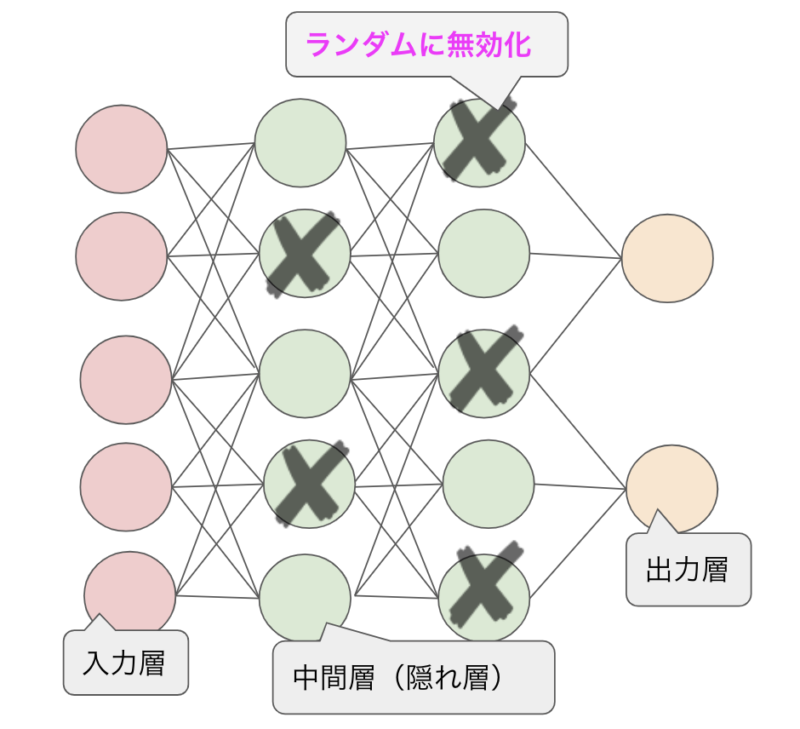
訓練時にランダムでニューロンを消去していくことで、毎回異なるニューラルネットワークを学習するため、同じデータを学習をしないため、精度が上がります。
一般的に半分の50%程度を無効すると良いと言われています。
高性能である理由は、「アンサンブル学習」という方法の近似になるからとも言われています。
アンサンブル学習を知りたい方は以下の記事を参考にしてください(^ ^)
アンサンブル学習アンサンブル学習は英語では、ensemble learningです。これは日本語でいうと合奏を意味します。このイメージは1人の意見だけでなく、多数決などで多くの人の意見を取[…]

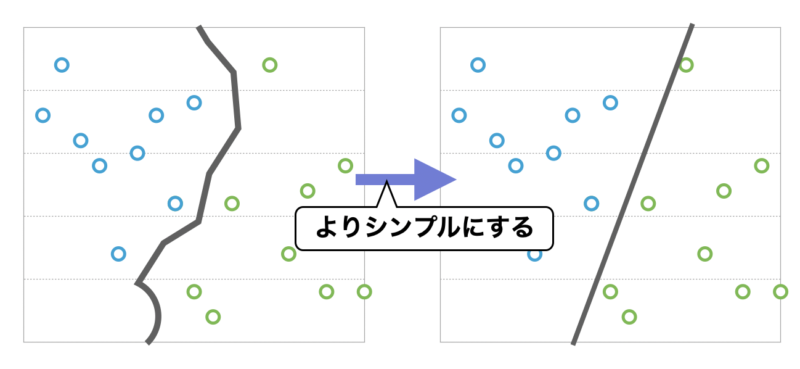
正則化
モデルの本質を表現するために必要のない重みにペナルティを与えて、複雑になりすぎたモデルが訓練データの偏りのパターンを低減する手法です。
ざっくりいうと「極端だと思われる意見は聞かないようにする」です。
以下のような感じで、複雑なところをシンプルにするというイメージです。
正則化のイメージ
よく用いられる正則化には、L1正則化とL2正則化がありますので、その辺りをみていきたいと思います。
<L1正則化>
不要なデータの重みを0になるようにします。
言い換えれば、必要な入力を選びとるという方法です。
L1正則化を適応した線形回帰を「Lasso(ラッソ)回帰」と言います。
<L2正則化>
極端なデータの重みを0に近づける
言い換えれば、重みが極端な値を取ることを抑える方法です。
L2正則化を適応した線形回帰を「Ridge(リッジ)回帰」と言います。
早期打ち切り (Early Stopping)
学習の反復(エポック)において、訓練データとテストデータを監視し、予測するモデルの値が悪化し始める所で学習を早期に打ち切る方法です。
以下のような感じのイメージです。
早期打ち切りのイメージ
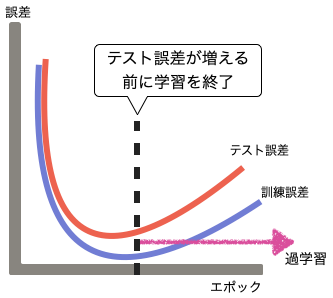
ある箇所から誤差が大きくなるので、早めに学習を終了する方法です。
まとめ
過学習になってしまう事で、予測精度が落ちてしまいます。
それを防ぐ方法を今回、ドロップアウト・正則化・ 早期打ち切りの3つご紹介しました。
難しいところもありますが、ぜひ少しずつ理解していきましょう!
もっと勉強したいと思った方はプログラミングを始めてもいいかもしれません。
